жївЊЙІФмФЃПщЁП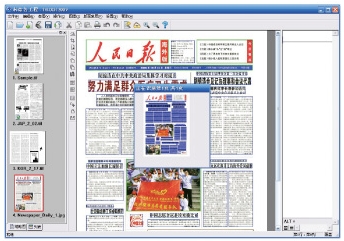
Ёё ЪЖБ№КЫаФ
TH-OCR 2009ЮФЭЈЪ§ОнТМШыЙЄГЇФкжУЮФЭЈЙЋЫОзюаТбаЗЂЕФИпадФмЮФзжЪЖБ№в§ЧцЃЌжаЮФЪЖБ№ТЪДя99.8%вдЩЯЁЃгЂЮФЁЂШеЮФЁЂКЋЮФЕФЪЖБ№ТЪОгЪРНчСьЯШЫЎЦНЁЃ
Ёё UNICODEБрТы
ВЩгУUNICODEЙњМЪБрТыБъзМЁЃЯЕЭГПЩдквЛИіЭГвЛЕФЦНЬЈЯТЃЌЭЌЪБДІРэАќРЈжаЮФЁЂШеЮФЁЂКЋЮФЁЂгЂЮФдкФкЕФЖржжЮФзжЕФЪЖБ№КЭаЃЖдаоИФЁЃ
Ёё XMLММЪѕ
ЯЕЭГЛљгкПЊЗХЪНЕФXMLЪ§ОнНсЙЙЃЌПЩвдЖдЪ§ОнНјааРЉГфКЭдйЖЈвхЁЃжЇГжЕкШ§ЗНПЊЗЂГЇЩЬЗНБуЕиНјааЮФЕЕЪ§ОнЕФзЊЛЛЁЂЧЈвЦКЭдйРћгУЁЃ
Ёё АцУцЛЙд
ЧПДѓЕФАцУцЛЙдММЪѕЃЌПЩНЋЪЖБ№КѓЕФБЈПЏЁЂдгжОЁЂЭМЪщЕШЖржжаЮЪНЕФЮФЕЕЃЌЭЈЙ§ЛЙдзжЬхЁЂзжКХЁЂАцУцЮЛжУЁЂзжЬхбеЩЋЕШаХЯЂвддАцдЪНГЪЯждкЖСепУцЧАЃЌзюжеЩњГЩгХжЪЕФШЋЯЂPDFЮФЕЕЁЃ
Ёё МЏзжаЃЖд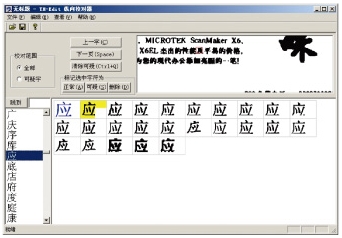
МЏзжаЃЖдЪЧTH-OCR 2009ЮФЭЈЪ§ОнТМШыЙЄГЇЬигаЕФЮФзжаЃЖдММЪѕЃЌИУММЪѕДђЦЦСЫДЋЭГаЃЖдЙЄОпЭМЯёгыЪЖБ№НсЙћЮФБОБШЖдЯдЪОЕФФЃЪНЃЌНЋЖрЦЊЮФЕЕжаЫљгаЪЖБ№НсЙћЯрЭЌЕФзжЗћЭМЯёМЏжаГЪЯждквЛИіЪгЭМжаЃЌИјаЃЖдШЫдБЧПСвЕФЪгОѕГхЛїЃЌШУДэзжздЖЏЁАЬјЁБШыаЃЖдШЫдБЕФблжаЃЌБмУтСЫаЃЖдШЫдБвђЯнШыЮФЕЕЕФЩЯЯТЮФгяОГЖјВњЩњЪгОѕЦЃРЭЃЌв§Ц№ЕФаЃЖдзМШЗТЪЯТНЕЁЃЭЌЪБЃЌгЩгкГЃгУККзжМЏжадк3000-4000ИізѓгвЃЌУцЖдКЃСПЮФзжЕФаЃЖдЪБЃЌВЛЛсвђЮФзжСПЕФЩЯЩ§ДјРДЯргІЕФаЃЖдСПЕФЩЯЩ§ЃЌШджЛашаЃЖдетМИЧЇИіВЛЭЌЕФККзжЃЌУїЯдЬсИпЙЄзїаЇТЪЁЃ
Ёё діСПЪЖБ№
діСПЪЖБ№ЙІФмдЪаэгУЛЇжЛЪЖБ№ЪжЙЄБрМаоИФЙ§ЕФЛђаТдіМгЕФЧјгђЃЌЖјБЃСєЦфЫћвбОЭъГЩаЃЖдЕФЮФзжЧјгђЃЌЮЊгУЛЇЪЙгУЬсЙЉзюДѓЕФСщЛюадгыЗНБуадЁЃ
Ёё здбЇЯАЙІФм
еыЖдЙХМЎЁЂПЦбаЕШЬиЪтСьгђЮФЕЕжаОГЃГіЯжЕФЬиЪтЮФзжЃЌМДЪЙВЛдкЙњМвБъзМЗЖЮЇвдФкЛђепTH-OCRзжПтжаВЂУЛгажЇГжЃЌгУЛЇвВПЩЭЈЙ§здбЇЯАЙІФмЃЌНЋетаЉЮФзжЕФЭМЯёбЇЯАНјШыЯЕЭГЃЌЪЙЕУЕїећКѓЕФКЫаФПЩвджЇГжетаЉЮФзжЕФЪЖБ№ЁЃ
Ёё ЫЋВуPDFХњСПжЦзїЙІФм
ПЩвдЪЕЯжЭМЯёЮФМўЕНPDFЮФМўЕФздЖЏзЊЛЛЃЌЩњГЩЕФPDFЮФМўФмЙЛЪЕЯжШЋЮФМьЫїЃЌПЩвдИДжЦеГЬљЃЌвВПЩвдЖдФГИіжИЖЈФПТМНјааГЄЦкМрЪгЃЌеце§ЪЕЯжЮоШЫВйзїЁЃ
ЁОЕфаЭгІгУЁП
ЭМЪщЙн
ЁЁЁЁ жаЙњЙњМвЭМЪщЙнЁЁЧхЛЊДѓбЇЭМЪщЙнЁЁЩЯКЃНЛДѓЭМЪщЙнЁЁЬьНђФЯПЊДѓбЇЭМЪщЙн
ЁЁЁЁ дкЪ§зжЭМЪщЙнСьгђгЕгаЩЯАйМвгУЛЇ
ЕчСІаавЕ
ЁЁЁЁ ЙњЕчаХЯЂжааФЁЁИїЪЁЪаЕчСІЩшМЦдКЁЁИїЪЁЪаЕчСІПЦбЇдК
ЁЁЁЁ дкЕчСІБъзМЪ§зжЛЏЯюФПжаЙуЗКгІгУ
ГіАцЩч
ЁЁЁЁ ЩЬЮёгЁЪщЙнЁЁжаЛЊЪщОж
ЁЁЁЁ дкЙХМЎЪЖБ№ММЪѕСьгђЕУЕНСЫПЭЛЇЕФЪзПЯ
БЈЖХ
ЁЁЁЁ ДѓСЌШеБЈЩчЁЁЩюлкЬиЧјБЈЁЁФЯЗНжмФЉ
ЁЁЁЁ дкЩњВњСїГЬЛЏЙмРэЯЕЭГвбГЩЮЊБЈвЕаХЯЂЛЏЕФЪзбЁвЊЫи
еўИЎЛњЙи
ЁЁЁЁ жабыАьЙЋЬќЁЁЙњМвАВШЋВПОХОжЁЁЫЎРћВПЁЁЙњМвжЪСПММЪѕМрЖНОж
ЁЁЁЁ ЭјТчСЫзюЖрЕФеўИЎЛњЙигУЛЇ
|



